Cut your inference costs in half.
The only LLM gateway that adapts to your traffic. Built for the fastest growing startups.
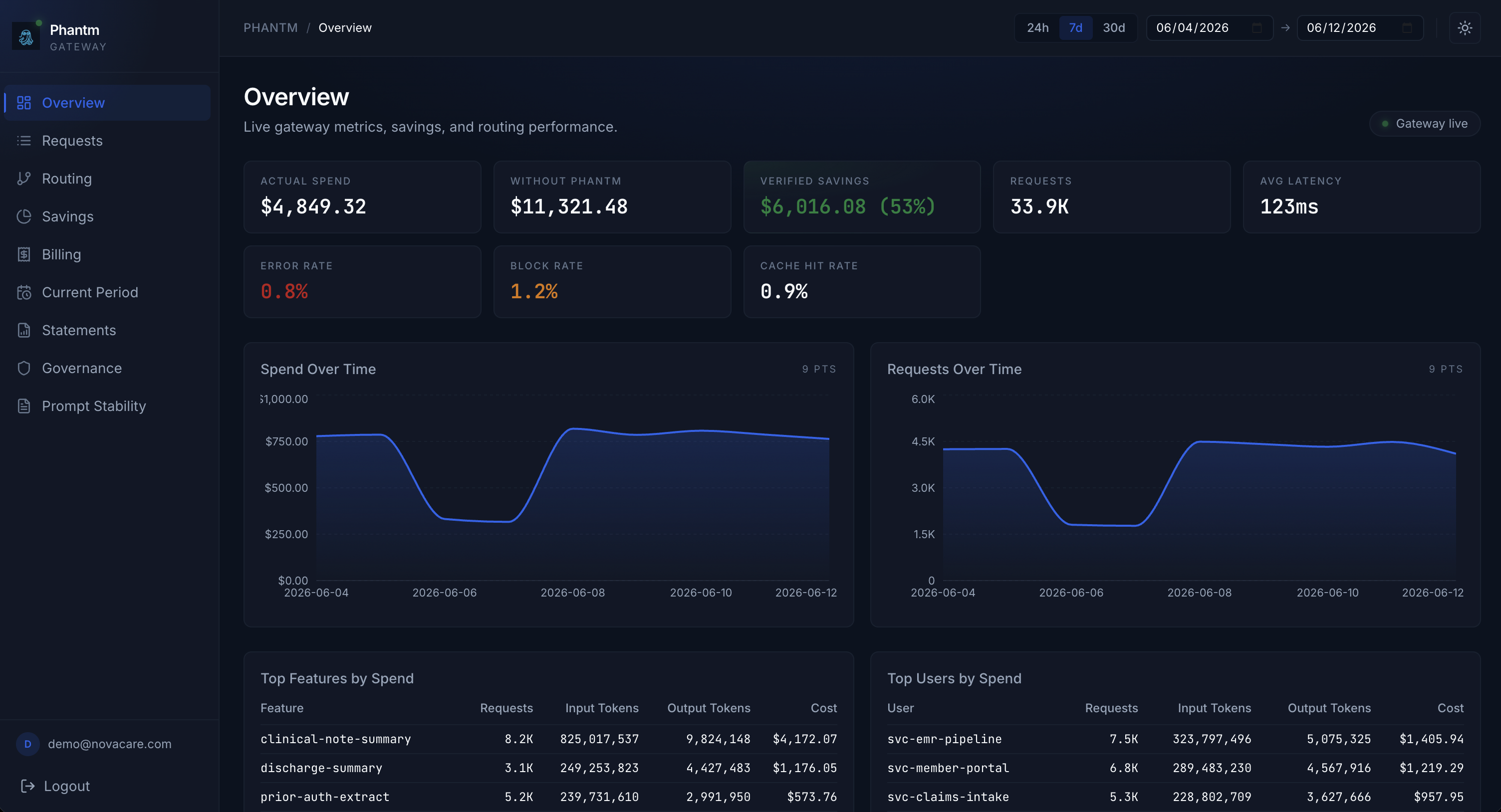


A new kind of LLM gateway. Purpose-built for production AI workloads, Phantm optimizes every request in real time.
Intelligent routing
Every request is scored for difficulty and routed to the cheapest model that can handle it, with automatic fallback when confidence drops.
Frontier compression
Prompts, context, and outputs are pruned and compressed before they reach the model. Fewer tokens in, the same answer out.
Seamless integration
OpenAI-compatible and drop-in. Point your base URL at Phantm and you are done. No SDKs, no workflow changes.
See what Phantm does to your prompt. Paste any prompt and watch the optimization pipeline run alongside OpenAI.
This demo runs on OpenAI. Anthropic, Gemini, and any OpenAI-compatible provider supported in production.
Measured, request by request.
We took 13,491 real requests, public benchmarks plus live customer-support traffic, and ran each one twice: once straight to the model, once through Phantm. Same prompts, same models.
Then we compared the bills and judged every answer. Response quality stayed indistinguishable from baseline, and every optimization traces back to a diff and a reason code.
Read the full evaluation13,491 requests · WildChat, LongBench, Hermes FC, and DialogSum, plus 6,991 production support prompts across 21 system prompts · May 2026
Every dollar, accounted for. The dashboard tracks spend by feature, user, and model as it happens. Budgets are enforced in the request path, not discovered on the invoice.
Live observability
Every request is logged with tokens, cost, latency, and the optimizations that fired. Spend rolls up by feature, user, and model while it happens, not at month end.
Budgets & limits
Set budgets and rate limits per tenant, feature, or API key. The gateway enforces them in the hot path. A request that would blow its budget never reaches the model.
Spend, explained
See which features burn tokens, which prompts bloat, and where routing saves the most. Monthly statements export straight to finance.






Meet the team.

-
 Owns pilots: outreach, qualification, closing
Owns pilots: outreach, qualification, closing
-
Runs product testing + customer proof artifacts
-
Research experience in NN fine-tuning + simulations; helped secure ~$2M Lily grant

-
Architect: leads product and system development
-
Experience building predictive systems
-
International Math + Physics Olympian

Get in touch
Let's talk.
Questions, pricing, or want to run a pilot? Drop us a line and we'll get back to you within a day.